Unit 12: Politics, Identity, and Representation in Multimedia
Synopsis
We argue that representation does not exist, and yet illusions of causality and interaction between bodies, movement, and media persist and have very real effects in the world, thus warranting deep consideration on an aesthetic and ethical level. Drawing on feminist and process philosophies, we probe shifting distributions of agency and intelligibility within and between differentiated “things” – gestures, sounds, bodies, identities, disciplines. Moving fluidly between examples from dance, music, interaction design, machine learning and artificial intelligence, we foreground concerns related to inscribed bias and systemic inequality in the design and use of technologies in art and life, as well as the ways in which mediums of representation are always already entangled within situated understandings of what it means to be human.

Representation
Identity is a tricky concept; can an object be identical to another object? Probably not. Can it be identical to itself? Maybe, but in order to make that comparison, we’d need to have a pretty good understanding of how to differentiate an object from other objects such that we can talk about the object itself. We’re essentially describing Leibniz’ principle of the Identity of Indiscernibles, which is a controversial proposition: it states that if we have two things, and we are not able to tell them apart, they must be identical, and since identity is a comparison with oneself, there must be only one thing. Especially today, in an age of digital and mechanical reproduction, we often see things that are indiscernible, like these two images.

Are they the same? I mean, really the same? Is there only one image? That question is complicated: on the one hand, we can say for sure that one of them is closer to the left hand side of the window and the other closer to the right, or similarly, we could say that the sequences of bytes that represents these images are in two different physical locations in memory on a computer somewhere. On the other hand, we have to ask whether or not those properties are actually properties of the images we’re trying to compare or not. The question is about intrinsic and extrinsic properties; is the location of an object in space and time a property of the object itself?
Let’s try this again, this time with some sound:
|
| |
Click the “play” button, and you should hear a sequence of clicks; again, we can ask a similar set of questions, and again it’s complicated. I made this using Max/MSP, so I had a software interface to a digital audio system, and that software ensured that every 44099 samples a single sample would have a value of 1.0, while the rest would be 0. Of course, those digital values have to be converted by the audio subsystem and hardware on our computers into voltages that drive our speakers, which then create pressure waves in the air. Once those pressure waves arrive at our ears, they are transduced through skin, bone, fluid, and eventually become electrical signals again, so it’s difficult to say what exactly the clicks are that we’re trying to compare. But let’s say for the moment that the clicks are the same—let’s say that they’re exactly the same enough that if one of them sounds different than the others, that’s probably telling us something about the room we’re in, or the position of our heads relative to the speakers, but we wouldn’t assume that it means one of the clicks was really different.
This is the sort of casual judgement of similarity or sameness that we make constantly—if we didn’t possess the ability to cognize certain things as being the same as each other, like these clicks, or these images, we’d have a very hard time accomplishing the tasks necessary to meet our most basic needs in the world. That said, what we want to acknowledge here is that when we do make those judgements of sameness, we do so at the expense of their differences. Again, this is absolutely a necessity of functioning in the world, and in fact we often don’t have to bother with these annoying questions of ontology—many of the differences that exist between objects that otherwise appear to be the same simply don’t matter, and don’t need to matter, in a given context. In this text, however, we will continue to return to them, even when they seem trivial, as a way of putting pressure on latent assumptions about the relationships between “things” and other “things”.
So let’s be clear here: if we have two things that are difficult to distinguish, that doesn’t make them indistinguishable—it’s just difficult to tell which is which. The Identity of Indiscernibles is an ontological question, not often helpful in daily life. That said, if we say that two objects that share exactly the same set of properties are identical, it must also be true that two objects that are not identical cannot share the same set of properties. When taken seriously, this is a reminder that when we judge things to be “the same”, what we really mean is to say is that “in this context, the differences between them don’t matter.”
This is a version of what Alfred North Whitehead calls the “fallacy of misplaced concreteness”. Let’s imagine that we would like to say something about where an object is in space at a particular time. In order to do this, we need to use other objects as a reference. But for Whitehead, there really are no stable objects, only change, only movement; we cannot say that an object occupies a particular location in space at a particular time, because those particularities require a discretization of space and time that simply doesn’t exist. He calls this type of location “simple location”, and despite the fact that we rely on it every day, it’s not real—it’s an abstraction of reality, even if it’s a necessary one. The fallacy of misplaced concreteness happens when we mistake that abstraction for the concrete facts of the world. So, if we live in a universe where the only constant is change, the notion of identity, which requires a set of essential properties (or predicates) in order to function, must also be an abstraction. It is not these essential properties that define an object, then, but the other way around: it is the question of identity that defines these properties. Or rather, it is us that defines these properties so that we may ask about identity.
So, to put the premise of this talk in simple terms: We don’t believe that representation exists. Representation is the establishment of a relationship between objects that configures one of them as represented, and the other as representation. Representation occurs through performance, intentional or unintentional, explicit or implicit, that constructs and sustains this relationship. The essential properties of the object to be represented must be fixed in order for representation to occur, but importantly, the essential properties of the object to be configured as representation must also be fixed—they do not derive in some way from the object configured as represented.
Interaction and Relationality
Things-that-interact
Although we do not believe that representation exists, we remain curious about the conditions under which illusions of representation persist, and further, about the effects of performances of representation in different contexts. As a choreographer and composer, we frequently produce what could be interpreted as representations of bodies and movement through our use of motion tracking and biosensing technologies. We might go so far as to say that we do not know how or if it is possible to do anything but perform representation when designing interaction between bodies and media in performance—and thus, it would be a mistake to ignore the notion of representation altogether, illusory as it may be.
If we think of representation as a sustained relationship that
requires the construction of:
(a) the thing being represented, and
(b) the thing performing this representation
we might also ask about the status of (c), that is
(c) who or what is engineering this relationship of representation
between (a) and (b), and
(d) the context in which (c) is performing, such that a relationship
of representation between (a) and (b) is conceivable
and desirable.
Let’s address the construction of (a) and (b) first, as things that become subject to interpretations of interaction and representation. If we want to represent something—an object, a gesture, a body, a sound—we have to make assumptions—implicit or explicit—about what this thing is, and therefore, what this thing is not. In his book, Form and Object: A Treatise on Things, philosopher Tristan Garcia takes a deep dive into questions regarding how things become intelligible through their differentiation from all that which they are not. In his terms: “the formal condition of a thing is everything except itself” (Garcia, 2014).
For the sake of example, let’s say that thing (a), that is, the thing to be represented, is a gesture. If I wave my hand side to side like this
when did my gesture begin? Did it begin as I lifted my arm from my lap, or as I tilted my hand to the side, or perhaps even earlier as I prepared to initiate this gesture as a demonstration of its thingness? And when did my gesture end? Did the wave of my hand end as I started to lower my arm? Or perhaps when it left the screen? If you continue to think about my gesture, has it actually ended yet?
Now let’s say we want to capture this instance of a thing-we-call-a-gesture using a motion tracking system, such that when I wave my hand in front of the camera in a particular way, it triggers changes in parameters of a projected image or sound.
If the gesture of waving my hand is to be defined as a discrete “thing” that can be consistently captured and represented based on its effects on (b), (b) must learn to identify and respond to (a) in a reproducible manner. In the ongoing process of identifying and representing (a), that which constitutes (b) is also subject to reconfiguration.
Thus, the question here is not only regarding the boundaries of the thing we wish to represent, that is, thing (a), but also about the boundaries of (b), that is the thing performing representation. Furthermore, we should not ignore (c) and (d), which relate to how and by whom both (a) and (b) became individual things available to interact with one another in what we have described as representation. Importantly however, the notion of interaction can only account for (a) and (b)—not (c) and (d)—a point we will return to in a little bit.
So how are the boundaries of (a) and (b) configured in relation to one another? Garcia refers to the ongoing processes through which things become discretized as “reification”. Reification is not a singular or closed event, but rather a relational process that is always already underway and without end. In ongoing processes of reification, each thing that produces another thing is itself produced by another thing. In Garcia’s words:
Something other than themselves always reified them, exposing their limits, determinations, and particularities, before subsequently reducing them to the rank of a particular thing, in an infernal chaos of thought. Everything that made things was made a thing, as if the executioner was condemned to be executed by an executioner, forced to be subjected to the same fate. (Garcia, 2014)
In this line of reasoning, there are no things—no gestures, no sounds, no bodies—that are not subject to reification. A thing must be, or rather become reified through its differentiation from other things, which are in turn reified by other things. Reification is a necessary precondition of representation. If we want to represent something, we have to have a thing to represent. Thus, we cannot avoid reification and representation.
It is important to note however, that reification, like representation, is never a value-free process. Reification involves the continual and asymmetrical redistribution of agency within and between things such that they come to matter in different ways. The differences engendered between things through processes of reification are not in themselves good or bad, but they do have effects in the world. As Garcia argues:
Reification—the reduction of our world to a world of things—is not an evil, the dehumanisation, desensitisation, or disenchantment of the world, but the precondition of a human understanding of the differences between things. A system of exceptions in the world of things is never an ‘ethical’ or ‘just’ system, but rather a metaphysical system of the determination of inequalities between things, of ‘more-than-things’, which cannot be elements of this system. (Garcia, 2014)
What Garcia reminds us, is that we, as individual people differentiating between things, are not outside of the systems of reification through which things become differentiated, and therefore identifiable and representable. In order to distinguish between things—which we must do in order to function—we each rely on our perception of differences between things within our frame of reference. These differences are not stable, but contingent, and dependent on the context in which we find ourselves in relation with other differentiated things.
Importantly, there is a directionality to the way that things become reified within our individual frames of reference. In order to identify a thing as one such thing, we must identify its boundaries, its limits, the point at which it is no longer consistent with itself—for us—without actually determining the ontological status of this thing beyond our relationship to it. This process of reification within our frame of reference is not only a matter of personal interpretation, but rather invokes entangled cultural, social, political, historical, ethical, aesthetic, and technological forces. And as I already mentioned, the notion of interaction between one thing and another does not in itself account for the role of designers within the contexts of design and implementation.
Intra-action
So, having considered how (a), the thing to be represented, and (b), the thing performing representation, are constructed relationally by way of reification, let us now consider the role of (c)—that which or those whom are engineering this relationship of representation, and (d), the context and conditions in which interpretations of representation become conceivable and desirable.
Returning to our example of waving, if I want to design an interactive system in which the movement of my gesture affects parameters in the sound and visuals—at its most basic level, a “Mickey Mousing” effect—I must narrow the scope of interaction to cause and effect between (a) and (b), and make myself invisible as the wizard behind the curtain orchestrating this illusion of causality and representation either in real-time, or by setting parameters of interaction in advance. The illusion of causal interaction and representation between (a) and (b) requires that (c), the designer of interaction, along with the context of interaction, be removed from the equation. The moment that (c) joins (a) and (b) in the spotlight, the illusion is broken, and aesthetic and ethical questions may arise regarding how and why such an illusion of causality and representation was constructed and sustained.
Admittedly, the stakes in this example are very low. Who cares how or if my gesture of waving is represented within a system of interaction? The point here, however, is not about the limits of representation of pre-constituted things, but rather about how the designers and context of interaction can become invisible within the representations produced. If we pivot to discussing representations that involve gender and race, as we will to some extent later in this talk, the importance of questioning local and systemic influences that affect design at the level of hardware and software, as well as implementations in performance, becomes increasingly clear.
For any one thing that we call interaction, as a causal relationship between pre-constituted things, if we simply widen the frame to include a broader apparatus through which an interpretation of interaction is produced—and this may include the designers of hardware and software, the choreographers and composers using and adapting these technologies, the performers, audience, and users, and also, the broader social, cultural, and historical context of performance—we see that representation, causality, and interaction are only meaningful given a particularly narrow framing of the relationships and agencies involved in producing such correlations between differentiated things, without accounting for how these things became reified and available as objects of interaction in the first place.
In a recent article in the Journal of Performance Philosophy, we argue that:
the approach of any designer to shaping relationships between “things” (e.g. bodies, data, or ideas), positions the designer in relation to these “things” as objects of interaction, without precluding the designer being one of these objects. This design process is grounded in understandings of what these things are as objects of interaction, and therefore, what they can do, that are rooted in the conceptual frame and intentions of the designer. (MacCallum et al., 2019)
Widening the frame from the design of interaction between pre-constituted things, we argue in this article that in order to account for the role of the designers and design context within processes of reification and representation, we must shift the lens from designs and interpretations of interaction, towards to the notion of intra-action, as proposed by philosopher and quantum physicist Karen Barad. This means reimagining the role of the designer / choreographer / composer / director / programmer such that they are no longer cast as the wizard behind the curation, but instead understood as integral to the production of contingent differences between things-that-interact. The notion of intra-action is not a replacement for interaction—rather, our use of the notion of intra-action in the context of design practices such as choreography and composition invites interrogation of the ways in which human values and beliefs become inscribed within systems of interaction—systems which have effects beyond the immediate intentions and actions of the designers.
Speaking on the relationship of interaction and intra-action, Barad explains that:
The neologism “intra-action” signifies the mutual constitution of entangled agencies. That is, in contrast to the usual “interaction” which assumes that there are separate individual agencies that precede their interaction, the notion of intra-action recognizes that distinct agencies do not precede, but rather emerge through, their intra-action. It is important to note that the “distinct” agencies are only distinct in a relational, not an absolute sense, that is, agencies are only distinct in relation to their mutual entanglement; they don’t exist as individual elements. (Barad, 2007)
So what does this mean in practice? What does it mean to create, design, and perform intra-actively? One point that is key to understanding the difference in Barad’s framing of interaction versus intra-action, is that it suggests an ongoing redistribution of agency between human and nonhuman performers in the unfolding of relational events. Rather than designers determining the behaviour of things-that-interact through direct and intentional control, designers working from an intra-active perspective might imagine their role as being to shape a context in which relationships emerge between performers, animate and inanimate, in ways that exceed their own immediate frame of reference or aesthetic vision—yet remain informed by it.
Postmodern composers and choreographers working with chance operations, such as Cage and Cunningham, lead us in this direction. In throwing the dice to determine the next move in an event, some degree of control is transferred between the dice thrower and the dice—although only to the extent of combinations permissible by the numbers of the dice, and only in relation to the pre-composed materials to be performed in response to this composed action of throwing the dice at a particular moment, for a particular purpose.
More contemporary examples of artists working with scores for improvisation in movement, music, and multimedia likewise endeavour to embrace a distributed and relational approach to performance in which nonhuman agencies, for example the agency of objects, images, sounds, and movements all contribute to the becoming of an event. In his book Media Ecologies, Matthew Fuller embraces the notion of ecologies to foreground non-anthropocentric interpretations of relationality in multimedia performance. Fuller argues that:
Ecologies focus rather more on dynamic systems in which any one part is always multiply connected, acting by virtue of those connections, and always variable, such that it can be regarded as a pattern rather than simply as an object. (Fuller, 2005)
If you have read Deleuze and Guattari, you might notice the striking resemblance in the above passage to their description of the rhizome as a metaphor for the nonlinear and processual emergence of heterogeneous relationships within an ecology, or what they would refer to as an assemblage. As a parallel metaphor, consider that whereas trees grow vertically from roots, to trunk, to branches, to leaves, rhizomatic structures are everywhere already connected, such that “any point of a rhizome can be connected to anything other, and must be” (Deleuze et al., 1987). The points of a rhizome do not precede their connections within a rhizome, and later require someone or something to connect the dots; rather, the multiplicity within a rhizome involves continual reconfigurations and redistributions of points of relation, such that these points only come to matter through their heterogeneous connections. These connections are not stable or fixed, but rather emerge via the continual lines of movement and relation between them—even as they themselves remain in flux.
Connecting the metaphor of the rhizome to performance, Deleuze and Guattari offer us the following example:
Puppet strings, as a rhizome or multiplicity, are tied not to the supposed will of an artist or puppeteer but to a multiplicity of nerve fibers, which form another puppet in other dimensions connected to the first: Call the strings or rods that move the puppet the weave. It might be objected that its multiplicity resides in the person of the actor, who projects it into the text. Granted; but the actor’s nerve fibers in turn form a weave. And they fall through the gray matter, the grid, into the undifferentiated […] (Deleuze et al., 1987)
In this passage, Deleuze and Guattari complicate a very common example of what could be interpreted as unidirectional control between puppeteer and puppet. In illustrating how agency is distributed between performers of all animacies at the level of materiality, they challenge binary interpretations of interaction between subject and object, and likewise source and representation.
Turning to a musical example, Deleuze and Guattari emphasize that the complexity of relationships within rhizomatic structures are not something that can be captured or measured through the lens of causal interaction. In their words:
When Glenn Gould speeds up the performance of a piece, he is not just displaying virtuosity, he is transforming the musical points into lines, he is making the whole piece proliferate. The number is no longer a universal concept measuring elements according to their emplacement in a given dimension, but has itself become a multiplicity that varies according to the dimensions considered […]. (Deleuze et al., 1987)
The provocation that Deleuze and Guattari provide us here has the potential to be extremely disruptive with regard to the design of interaction in multimedia performance. The very basis of many practices involving motion tracking and motion capture, as well as biosensing, is the discretization of continuous processes into identifiable points of data that can then be interpreted in relation to one another. But if these points are not discrete, then moving between moving points, even as these points extend into lines of flight, necessarily requires new strategies for engaging with design, choreography, and composition.
Both Barad’s notion of intra-action, and Fuller’s notion of media ecologies, align with the emphasis on multiplicity and heterogeneity in Deleuze and Guuattari’s metaphor of the rhizome. These three articulations of relationality invite us to reimagine human agency in tandem with inanimate objects and environments—and the implications of this are significant with regard to what it means to be a person trying to direct things, in art and in life.
Of course, these are just a few selected examples from a broad body of discourse on issues of representation and interactive performance, and many other practitioners in the arts, humanities and sciences have addressed these concerns over the past decades, or even centuries. When discussing the notion of relationality in artistic encounters, Nicolas Bourriaud’s book on Relational Aesthetics from 1999 is widely cited. Regarding interactivity in art, Bourriaud reminds us that:
Suffice it is merely to re-read the lecture given by Marcel Duchamp in 1954, titled “The Creative Process”, to become quite sure that interactivity is anything but a new idea… Novelty is elsewhere. It resides in the fact that this generation of artists considers inter-subjectivity and interaction neither as fashionable theoretical gadgets, not as additives (alibis) of a traditional artist practice. It takes them as a point of departure and as an outcome, in brief, as the main informers of their activity. The space where their works are displayed is altogether the space of interaction, the space of openness that ushers in all dialogue […]. What they produce are relational space-time elements, inter-human experiences. (Bourriaud, 1998)
So already in 1999, speaking about prior decades, Bourriaud was recasting interaction as a matter of relationality between artist, artwork, audience, and context. Many other artists and scholars, largely those whose work is informed by process philosophy, have continued to deepen discourse about relational aesthetics.
For example, Erin Manning’s writings, in particular her book Relationscapes, take on challenging questions related to the abstraction and representation of movement—not only the movement of the human body, but also the movement of thought (Manning, 2009). Manning urges us to consider movements that have not yet taken perceptible form, by attending to the “incipience” and “pre-acceleration” of movement, that is, to the intervals out of which movement emerges. Manning’s emphasis on the continuous and relational becoming of movement calls into question what is actually being captured and represented when we map causal relationships between already actualized movements and media—which do not exist without intervention into their continual becoming.
A key premise in process philosophy, and in this talk, is that movement is always present—it follows, then, that any determination of where one movement ends and another begins is an aesthetic judgement, grounded in one’s practice and perspective, and inscribed in technologies of capture that in turn govern the visibility and perceptibility of certain movements at the expense of others. When the notion of mapping interaction is applied to movement, one can only ever reduce and flatten the dimensionality of the dynamic flows integral to any process of intra-action, such that it is misrepresented as a matter of binary interaction.
So far, we have been drawing on many philosophers who challenge the notion of representation from the point of view of the procesual emergence, or immanence, of all objects and identities without the need or possibility of fixing stable relationships of causality and interaction between them. You may presently be wondering how these philosophical threads apply concretely to artistic practices involving multimedia.
The primary reply we want to make in this regard is that we have no intention of using philosophy to explain or interrogate artistic practice, nor do we wish to position artistic works as illustrations of philosophical concepts. Instrumentalising one disciplinary or cultural practice in service of another will only harm them both by flattening aspects of their methods that matter to them. We are not interested in how philosophy and performance interact—that is, how they act upon one another from without. Rather, our curiosity lies in how philosophy and performance are always already in dynamic, intra-active relation. Afterall, the boundaries between philosophy and performance are not so clear cut from either a historical or contemporary perspective.
We do however want to offer some examples, or thought experiments if you will, that begin to illuminate the stakes of beliefs about identity and representation in artistic practices involving multimedia.
Bodies and Boundaries
Bodies That Matter
Thus far, we have discussed examples that have little significance with regard to the effects of exclusion that are a requisite aspect of any act of representation. In the coming part of the talk, we will turn our attention to representations of human bodies that have explicit ethical and political implications.
To begin, we must ask: what is this thing-we-call-the-body?
If we want to represent the body, or if we are looking at a drawing
or sculpture intended to represent the body, we must have some
preconceived notion of what the body is, and more specifically,
what a human body is—as well as what it is not.
Garcia asks a similar question:
Is a human being a certain ‘something’, a thing, as a result of its organic unity, its logical unity, or its arithmetical unity? Unquestionably, a coherence exists—a series of relations that connect this human being’s bodily limbs, tissues, and functions to a biological and physical interdependence identifying this material thing as an organism. (Garcia, 2014)
So for some, the human body could be understood as a composition of material parts, operating cohesively and logically through relationships beneath the skin. In other words, the skin is cast as the boundary of the body, differentiating it from each and every other body, such that it is identifiable and countable as one such body among bodies. Garcia continues, shifting from the notion of the “body” to the notion of a “human being”:
But a human being is one human being only insofar as it counts among human beings. Unity is primarily the possibility of being counted, of entering into the count. To be one is to be capable of being one of two, three, ten, and so on. To be one is to be capable of acting as a unity in the counting of that which one is, since one is one something. (Garcia, 2014)
Thus, for Garcia, the human body is not a thing in-itself, but rather a thing among things, defined through its relation to other such things. But what does it take for a body, or a human, to be countable?
As history has taught us, not all bodies, and not all human beings, are counted in the same way, or even at all, in systems of cultural identification and representation. Think for example of recent controversies surrounding algorithms for facial recognition that either misidentify or fail to recognize black people as people at all. These algorithms are based on Machine Learning, designed by other humans, and trained using selected materials in particular contexts. So the question is, how much difference can a facial recognition system accommodate within its conception of a human face, as a collection of pixels, before someone no longer counts in its eyes—but really, in the eyes of its designers—as human?
Several recent publications and projects address ongoing issues of inscribed bias and racial discrimination in the realm of Machine Learning (ML) and Artificial Intelligence (AI), with much greater nuance than is possible here, so I will point you in their direction. A few excellent resources include Safiya Umoja Noble’s Algorithms of Oppression (Noble, 2018), Ruja Benjamin’s edited volume Captivating Technologies (Benjamin, 2019), and finally the Algorithmic Justice League which is an initiative founded by Joy Buolamwini (Algorithmic Justice League, 2020).
We will return to discussing ML and AI later in our talk, but for now I want to stay with the question of what constitutes the thing-we-call-the-body.
In the book, Bodies that Matter, philosopher and gender theorist Judith Butler acknowledges the necessity to formulate particular constructions of “the body”, at the same time as we call into question what is included and excluded from these constructions. Butler asks:
What are we to make of constructions without which we would not be able to think, to live, to make sense at all, those which have acquired for us a kind of necessity? Are certain constructions of the body constitutive in this sense: that we could not operate without them, that without them there would be no “I,” no “we”? Thinking the body as constructed demands a rethinking of the meaning of construction itself. (Butler, 1993)
Underlying this passage, and Butler’s work at large, is a questioning of the ways in which bodies become reified as particular things that can be represented, through the constitutive exclusion of all that which they are not. Part of the way in which human bodies become reified is through the assignment of gender classifications such as male and female. Such classifications are never objective reflections on “natural” or “biological” bodies, but rather express cultural understandings of the significance of anatomical differences in the production of one’s identity. In this call to rethink the meaning of construction itself, Butler invokes long-standing tension between the binary notions of biological and social determinism in Western philosophical discourse about bodies.
To briefly explain: in what could be interpreted as a response to the severe and tragic consequences of practices associated with biological determinism such as Phrenology and Eugenics from the late 18th century to present day, feminsit scholars such as Butler have strongly insisted on the ways in which bodies are constructed culturally, rather than being mere expressions of a “natural” or “material” essence. However, this framing of cultural inscription, that is, the idea that the body is a blank slate onto which cultural significance is inscribed, has had the unintended consequence of stripping interpretations of the material body of its agency to affect change in the world.
So, although we may argue in the vein of process and feminiist philosophy that the notion of gender is constructed and distinct from biological sex, we must still take into account the very real effects that cultural constructs such as binary gender have on people’s lives, in particular with regard to their visibility and agency within systemic power structures. As Butler cautions:
[…] it is not enough to claim that human subjects are constructed, for the construction of the human is a differential operation that produces the more and the less “human,” the inhuman, the humanly unthinkable. These excluded sites come to bound the “human” as its constitutive outside, and to haunt those boundaries as the persistent possibility of their disruption and rearticulation. (Butler, 1993)
The point that Butler makes here regarding the persistent possibility for boundaries to be disrupted and rearticulated is poignant; what Butler reminds us, is that bodies and identities, or rather, the processes of differentiation through which bodies and identities become distinct, are never closed or stable. This premise applies at the scale of individuated human bodies and identities, but also to boundaries on a larger scale, such as the boundaries of communities, disciplines, countries, and cultures. Inclusion within the boundaries of a given thing is always at the expense of the exclusion of other such things.
Stilled Bodies
If we agree with Butler that the boundaries of bodies are subject to continual reconfiguration, what are we then to make of seemingly static representations of bodies and identities that are removed from these processes of relational becoming? When we freeze a body in time and space—for example in a sculpture or statue, or as a plastinated corpse—in what ways are the boundaries of the body still subject to disruption and rearticulation? When a body is captured as such, stripped of immediately sensible liveness and movement, how does it continue to perform, relationally?
Thinking on the history of sculpture and the “sculptural encounter” from a relational perspective that might be likened to Bourrauld’s relational aesthetics mentioned earlier, David Getsy writes:
A three-dimensional figurative image—that is, a statue—both depicts a body in space and is a body-in-space. I can look at a statue of an athlete, of Apollo, of a fieldworker, of a politician, of a heroine, or of a fawn and see it in its representational distance. I am confronted by an image of something not actually present, perhaps never seen in everyday life, or maybe recognized as a character from books, poems, dreams, or the televised news. At the same time that it functions in this way as a three-dimensional image, the statue is also present for me as a physical object displacing space with its volume. It stands, sits, or lies in front of me. I can touch it. I do touch it. I walk around it. I move up to it. I walk away from it. (Getsy, 2014)
The “realness” of the statue in our experience of it, depends in part on how we perceive its agency in relation to our own bodies and identities. Yes, we can touch the statue—but then, is the statue also touching us? How does the unique materiality and temporality of a statue intersect with our own? Concerning the perceived animacy of sculptures, Getsy highlights the prevalence of discourse of realism in the tradition of European sculpture, He writes:
Indeed, figurative sculptors developed an arsenal of methods directed at imbuing their static bodies with the impression of life. They spent a great deal of energy trying to convey actual movement and the capacity for motility in their sculpted bodies in an attempt to convince viewers to look past the obdurate stillness of their works. Contrapposto, facial expressions, gestures, and other implied movements were all used to simulate motion and its capacities in unmoving anthropomorphic masses. Consequently, the most biting criticism of sculpture was to call it cold and lifeless. (Getsy, 2014)
Importantly, attributing realness, animacy, or agency to a sculpture, based on its effects in the world, requires attention to the context in which the sculptural encounter unfolds. One need only to observe the recent tearing down of Confederate statues in the United States and abroad as part of the Black Lives Matter movement to understand that such monuments represent not only the bodies and identities of individual figures, but also, the history and ongoing systemic effects of slavery, racism, and white supremacy. Thus, our judgments of the realism of a given statue ought to also consider the very real, ongoing effects that statues have in the world.
This imperative to project human qualities of liveness and movement into inanimate forms persists even in media that can represent movement through space and time more concretely, such as “moving pictures” and motion capture. But before we get to motion capture in a traditional sense, I want to consider another example of the animation of movement in stilled bodies—this time, actual human bodies—or rather, plastinated corpses.

In the Bodyworlds exhibit, advertised as both artistic and scientific, visitors are confronted with, quote “real human bodies” that have been preserved through plastination, and arranged as if suspended in motion. For example, there are athletes and dancers, suspended mid jump or turn. Stripped of their skin, such that we can view parts of their skeleton, musculature, and organs, the proposed social impact of the exhibit rests on the premise that we, as visitors, will see ourselves reflected in these anonymous, uncanny figures. Writing on the Bodyworlds exhibit in her book The Transparent Body, José van Dijck suggests that:
[…] plastinated cadavers prompted visitors to reconsider the status and nature of the contemporary body, both dead and alive. The contemporary body is neither natural nor artificial but the result of biochemical and mechanical engineering; prosthetics, genetics, tissue engineering, and the like have given scientists the ability to modify life and sculpt bodies into organic forms that were once thought of as artistic ideals: models and representations. (van Dijck, 2005)
The hybridity of these bodies as described by van Dijck invokes
discourse on cyborgs in the writings of
Haraway
and
Braidiotti—not
those portrayed in Hollywood films as a
potential future transformation and threat to the human race—but
rather as our reality, now, and indeed, since forever.
Integral to van Dijck’s project in discussing the notion of
the “transparent body” in relation to medical imaging technologies,
and likewise in posthumanist articulations of cyborg embodiment,
is the contention that there is no such thing as an unmediated
body, free of technological or discursive interference.
In other words, there is no such thing as a neutral or value
free representation of a human body or human being. And yet, as
the design and use of technologies for sensing and representing
bodies continue to proliferate, the urgency to address ethical
dimensions of such practices is increasingly palpable.
Commenting on public reception of the Bodyworlds exhibit, as well as controversy surrounding its development and marketing, van Dijck offers that:
Perhaps most unsettling about von Hagens’s plastinated cadavers is their implicit statement that the very epistemological categories that guide us in making all kinds of ethical distinctions simply do not apply here. Categories such as body versus model, organic versus synthetic/prosthetic, object versus representation, fake versus real, and authentic versus copied have become arbitrary or obsolete. Since we commonly ground our social norms and values in such categories, von Hagens’s anatomical art seems to elude ethical judgments. (van Dijck, 2005)
von Hagen’s intervention into the materiality of flesh to quite literally sculpt bodies according to his own vision is a striking illustration of the entanglement of aesthetic, ethical, and political concerns in the production of bodily representations in scientific and artistic practices alike. As representations of “the body”, these plastinates are expressly stripped of markers related to their personal, cultural, and racial identity. On the Bodyworlds website it states that:
As agreed upon by the body donors, their identities and causes of death are not disclosed. The exhibition focuses on the nature of our bodies, not on providing personal information (https://bodyworlds.com/about/faq/).
Implicit in this statement is the belief that one’s physical body can be disentangled from one’s identity. And, although unstated on the website, this anonymization of cadavers serves another purpose; by removing all obvious markers of identity related to culture, race, and in many cases gender, we are invited to interpret these “specimens” as universal examples of the “natural” body, akin to our own body regardless of our background.
This is, admittedly, an impressive illusion of bodily representation: in order for the plastinated cadaver to act as a representation of the thing-we-call-the-body—and not the body or identity of the actual donor, despite the continued presence of their flesh—we as observers must agree to sever this discursive act of representation from its material emergence. Further, we must ignore the extensive intervention on the part of the designers of this exhibit, including not only von Hagens but the multiple teams of scientists, artists, ethicists, lawyers, engineers, and managers, etc. involved in realising and touring this exhibit world-round, and more broadly, the historical and cultural narratives that make our belief in the value and veracity of such representations possible.
Zeroing back in on the premise of this talk: we believe that all representations are constructed. This is, in part, because all things, including bodies, are constructed by way of ongoing differentiation. As we have stated already, our position is not that representation is bad: rather, what we want to emphasize is that representations are only ever partial, and this partiality points to the beliefs and values of the human designers and context in which representation is performed, as well as to systemic inscriptions of values in technologies of capture and reproduction that are not easily traceable to distinct origins.
We will turn now to additional examples of bodily representation in the context of motion capture. Whereas we just discussed the animation of inanimate “bodies” by way of movement, or the illusion of movement, presently we will look at representations of movement, abstracted from its source and context.
Motion Capture
So, one question we want to ask is: How, when, by whom, and to what ends did “motion” become understood as something “capturable”? The early precursors to modern motion capture technology, for example, the chronophotography of Étienne-Jules Marey and Eadweard Muybridge, or Max Fleischer’s rotoscoping technique, both rely on sequences of still images. As a thought experiment, let’s pretend for a moment that this image by Marey

was faked—let’s imagine that it’s simply a single image of a fairly simple sculpture consisting of a number of similar white balls suspended from the ceiling. Even if that were the case, I think we could still relate to it through our sense of movement and motion. But our interpretation would be the same whether the image was faked or not—we’re still interpreting, we’re still filling in the blanks, and we’re invited to do so as part of the performance that links a still image to the concept of movement by way of the terms chronophotography and motion capture.
The role of the human interpreter here is crucial, and it is our conception of motion that we ultimately see when we consider these photos in the context of “motion capture”. More importantly, we may not all agree about what we see here. Which direction is the ball bouncing? I think it’s from right to left, but if we’re looking at a 2D image of a 3D room, is the ball moving from the back of the room towards us? Away from us? Or more or less laterally across the space? It might not matter now, but what does matter is that it is open to interpretation, and we can come to consensus, or agree to disagree.
In the case of semi or fully automated motion capture systems like the Kinect, some of that interpretation must be embedded in the system itself, that is, the system must have encoded in it a notion of what a body is, and how to identify it in an image. Of course, this conception of the body is necessary in order to be able to draw the skeleton that you’ll be familiar with if you’ve used the Kinect,
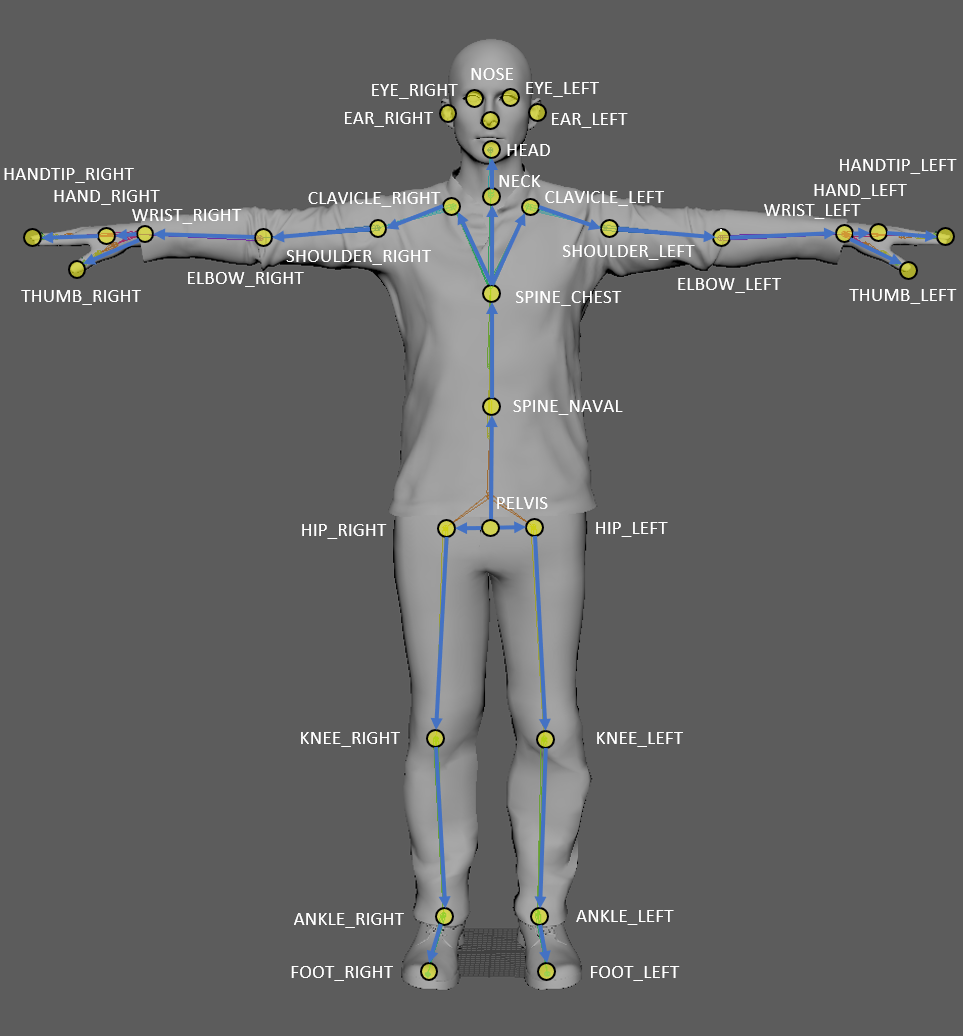
but more importantly, it’s crucial in order for the computer to be able to take two images, and associate some cluster of illuminated pixels in some region of one image with a similarly illuminated cluster of pixels in a different region in the next. We humans do this pretty well, after all, if we didn’t, watching motion pictures would be a strange experience. For a computer to do that, some of our basic assumptions about how a body is configured and how it moves must be encoded algorithmically into the system.
What happens when a body part becomes occluded by another?
From the point of view of a front facing camera, that body part has simply disappeared–there is no information to associate with it. These situations are interesting, because if you have a basic model of how the body is put together and what it can and can’t do, you can try to make some guesses about what’s going on with the parts of it you can’t see. These moments, when a system tries to guess what’s going on, can be wonderful opportunities for appropriation and misuse. (I remember the first time we brought a second generation Kinect from CNMAT into choreographer Lisa Wymore’s studio at UC Berkeley—the very first thing she did once we got it set up was a handstand :)
In contrast to markerless systems like the Kinect, marker-based systems are sort of more straightforward. Markers are placed on the body, and cameras designed to highlight those markers, perhaps using infrared light, pick them up. The challenge then, is to recognize which one is the left elbow marker for example, so you can connect it to the left wrist marker and so on. This is tough, but there are various strategies for it including active markers that communicate information that allows them to be uniquely identified more easily. This means that if you can differentiate the markers when processing the data, the analysis system doesn’t have to have such a rigid encoding of the body. If you do a handstand, it’ll still make the connections in the right way. In fact, you don’t even have to put the elbow marker on your elbow, you could put it on your penis, or wherever you want.
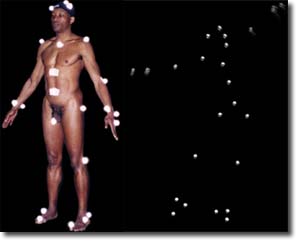
While a marker-based system may not need to have as rigid a conception of the body encoded in its analysis components, conceptions of the body abound in the system as a whole, a system which should be seen to encompass the entire apparatus, the room, its operators, its users, etc.
This image of choreographer Bill T. Jones is a beautiful example of the clash of two different conceptions of the body, one which sees it as markable, and one which does not. In describing his experience with motion capture systems, Jones said
They hadn’t really thought out the limitations of the sensors on my body…. Sure enough, once I began to sweat [the sensors] would pop off and then everything would stop…. And I said, ‘I don’t think your technology can actually capture what I do’. (De Spain, 2000)
Part of the promise of motion capture is that it will not only capture a sequence of images or a set of discrete points in space, but quite literally capture the movement of a person—not an abstract model of their movement, but their concrete, essential movement stripped free of the rest of their physicality and identity. In the very specific case of Bill T. Jones, there’s a lot to discuss here—too much for such a short talk—but perhaps we can at least bring the pertinent issues to the foreground. For a person who has been as outspoken as Bill T. Jones about his experiences as a gay, Black, man in the modern dance scene, and the relationship of those experiences tied to his skin color, sexuality, and gender to his movement, the prospect that his movement can be somehow separated from the rest of him runs the risk of configuring his skin color, gender and sexuality as something added on to him. This particular example of the fallacy of misplaced concreteness has the, I think, unintended consequence of configuring blackness and homosexuality as matters of style, reinforcing notions of white supremacy and heteronormativity. As Allison Reed and Amanda Phillips put it,
It is crucial to question the discourses of realism that surround motion capture technologies and the very representations they produce, which so often rely on the logics of white supremacy to ground reality in either the transparent universality of whiteness or the embodied specificity of people of color—what we call additive race, the reduction of racialized difference to a matter of style. (De Spain, 2000)
The use of motion capture to produce ghostly figures that move alongside Jones, without embodying or representing his lived experiences in the same way, opens generative questions regarding what is included and excluded in re-animations of bodies and identities in order to sustain interpretations of actual representation. Our concern here is not with the realness or authenticity of representations; we are working from the premise that all representations are partial, situated, and constructed. What we want to interrogate are the material-discursive conditions in which representations of bodies and movements come to matter in different ways, for different people.
Models, Notation, and Codification
Laban Movement Analysis
Now let’s consider an entirely different approach to motion capture. In recent years, the use of Laban Movement Analysis (LMA) in fields such as robotics and human computer interaction has become widely popular. Human movement is extraordinarily complex, and describing it even more so. LMA is a very useful and capable system, but actually performing LMA is a task usually reserved for certified experts with years of training. Just like practices of describing, communicating about, and notating music, LMA and its closely related symbolic system, labanotation, cannot account for all aspects and details of performance. Moreover, while a group of experts may find themselves in agreement about the generalities, they will often disagree nontrivially about the particularities.
Sha Xin Wei asks: “Why did Laban’s and his collaborators’ thirty years of titanic effort not yield a more universal language for movement and dance, a written form in which choreographic art could develop?” In his estimation, “notating dance is no more and no less impossible than fixing the written representation of all human speech practices. This points to much deeper problems with any sort of representation, whether of movement or of other living or social activity.” (Sha, 2013)
The point here is that despite the allure of an objective system for describing human movement, LMA and labanotation are not objective or universal, and just as with our discussions of motion capture a few moments ago, any attempts to model movement in the terms of a system like LMA requires an encoding of aspects the subjectivity of a particular analyst. That’s not such a bad thing, in fact, all computation, even the simplest operations, could be seen in this way. The addition performed by a computer is absolutely not the same as what you were taught in your math class in school; it’s based on a conception of addition that is assumed to be useful in an unforeseeable future spatio-temporal context. Likewise with machinic movement analysis; if one attempts to model, say, the effort of a human mover, one has to imagine the possibilities of what that body can do and be. Instead, what would have to be modeled is not effort, but the corporeally-situated practice of observing and describing effort.
Sha reminds us that
[w]e often mistake a thinker’s scaffolding for his or her conclusion, or pedagogical rhetoric for actual practice. Christopher Alexander’s approach and practice cannot be reduced to his set of “patterns” without entirely desiccating the approach and turning it into its deadly opposite. Likewise, Laban’s approach cannot be reduced simply to his system of notation. A common move by technicians is to reduce Alexander’s or Laban’s compositional approaches to a fixed schema or typology and try to build entire worlds by combinations of a set of primitive elements. (Sha, 2013)
Improvisation
George Lewis writes in similar terms about music. In a talk given in 2007, he said
Quite a few years ago I had a conversation about music with one of the founders of the field of artificial intelligence, an area that has had fruitful exchanges with the philosophy of mind. As we discussed his great love, keyboard improvisation, he maintained very strongly that he was not a composer, but an improvisor. I remarked that AI researchers working on music seemed to spend a great deal of time studying European composition and performance, hoping to reproduce the work of the great European masters by computer.
That seemed a bit odd to me; after all, the point of AI as I saw it was to get a computer to operate in the real world. The original notion of the Turing test, as I understood it, was that to convince you that the computer was really intelligent, it had to respond in lived real time to unexpected, real-world input. Constructing such a program would necessarily confront a set of issues that the Werktreue-based conception of music composition doesn’t usually address. So I suggested that the study of improvisation, or what he was doing everyday, might be more germane to the field as a whole. I must admit that I was very surprised by his very quick, curt reply: “You can’t study that.” (Lewis, 2007)
For Lewis, this question of improvisation vs what he calls “Werktreue-based” composition is deeper than the binary between the two that he seems to set up here. He’s not suggesting that we just change course, forget about composition and its performance, and concentrate on this other thing: improvisation. Rather, his insight is much deeper—for him, listening itself is improvisation, and in order to build a machine that might interpret music, improvised or not, one must first have an idea about how listening works. In fact this extends beyond music into other forms of interpretative machine communication such as conversation. He continues in the same talk:
Improvising computer programs both problematize and clarify constructed distinctions between human and machine, in ways that illustrate the radical position of Lucy Suchman that “I take the boundaries between persons and machines to be discursively and materially enacted rather than naturally effected and to be available … for refiguring” (Suchman, 2007)
[…]
Suchman was surprised to learn that AI-based conversational agents “make evident the greater contingency of competent machinic hearing” (Suchman, 2007). In fact, a theory of listening, hearing, and interpretation is at the root of any design strategy for interactive music machines, because we can understand the experience of listening to music as very close to the experience of the improvisor. Listening itself, an improvisative act engaged in by everyone, announces a practice of active engagement with the world, where we sift, interpret, store, and forget, in parallel with action and fundamentally articulated with it. (Lewis, 2007)
The statement that improvisation is “engaged in by everyone” is a critical theme for Lewis. It’s not just at the root of musical activity, whether that activity seems improvisational or not, it’s at the root of human activity.
But what I am coming to call the “condition” of improvisation is indeed open to everybody—as a human birthright that was expressed precisely in the fight for survival that millions of people around the world witnessed on their television screens, including Johannesburg, where I watched in horror and incredulity as the US administration seemed either completely at a loss as to what to do, or more ominously, appeared to be willfully and perhaps criminally negligent, concerning the real-time plight of those fighting to survive Hurricane Katrina’s levee-smashing onslaught. Meanwhile, moralizing US news commentators thundered self-righteously about “looters” from the comfort of TV studios, drawing moribund racializing distinctions between black “looters” and similarly positioned whites who were simply “trying to find food and water.”
Following James Scott’s formulation, the improvisations of Katrina victims may be read as one of a potentially infinite number of “forms of public declared resistance” to domination, enacting “public counter-ideologies propagating equality, revolution, or negating the ruling ideology” (Scott, 1990) […] In the end, people were simply trying to survive, and the poverty of response of the US government to Katrina lay, simply, in the staunch refusal to improvise—inability of “homeland security” and “emergency management” forces to analyze situations and respond to conditions in flexible and mobile ways—elements that are, not surprisingly, key to improvisation. (Lewis, 2007)
What I remember of watching the news of Hurricane Katrina is exactly as George Lewis describes—absolute chaos as people did everything they could in order to survive, while the government of the richest nation in the world failed to help them meet their most basic needs. As things settled over weeks and months, and people began to return to their homes and businesses, or rather, what was left of them, it became clear that communities of color were hit significantly harder than white communities. That seems crazy—to think that a hurricane could somehow differentiate between communities, or that somehow black and brown communities are just unlucky or something. Of course, that is crazy, and the answer is much simpler: New Orleans, just like many other cities in the US, has been intentionally organized along racial, economic, and ideological lines.
Lenticular Logic
Tara McPherson writes about the modular logic at the core of the so-called “UNIX philosophy”, as UNIX was being developed during the height of the civil rights movement in the US. The development of UNIX and the civil rights movement may seem to have little to do with each other—indeed, I’m well aware that they both happened in the same years, but I’ll admit that before reading McPherson’s paper, I had never really considered them to be part of the same historical moment. This is typical of what McPherson calls “lenticular logic”; lenticular printing is the use of lenticular lenses to produce a print whose image changes depending on what angle you view it from. According to McPherson,
The ridged coating on 3-D postcards is actually a lenticular lens, a structural device that makes simultaneously viewing the various images contained on one card nearly impossible. The viewer can rotate the card to see any single image, but the lens itself makes seeing the images together very difficult, even as it conjoins them at a structural level (i.e., within the same card). In the post–civil rights United States, the lenticular is a way of organizing the world. It structures representations but also epistemologies. It also serves to secure our understandings of race in very narrow registers, fixating on sameness or difference while forestalling connection and interrelation. As I have argued else-where, we might think of the lenticular as a covert mode of the pretense of separate but equal, remixed for midcentury America (McPherson, 2012).
She continues
A lenticular logic is a covert racial logic, a logic for the post–civil rights era. We might contrast the lenticular postcard to that wildly popular artifact of the industrial era, the stereoscope card. The stereoscope melds two different images into an imagined whole, privileging the whole; the lenticular image partitions and divides, privileging fragmentation. A lenticular logic is a logic of the fragment or the chunk, a way of seeing the world as discrete modules or nodes, a mode that suppresses relation and context. As such, the lenticular also manages and controls complexity.
Seeing the civil rights movement as somehow contained in its own historical narrative, separate from the development of UNIX, is itself an example of lenticular logic, even as the response to the civil rights movement in the US employed a lenticular logic to contain it, and the modular thinking at the core of the UNIX philosophy is as well predicated on this type of logic.
The UNIX philosophy encourages people to write code that is modular, simple—that is, it should only do one thing, and be easy to understand. You shouldn’t worry too much about your code being fast or efficient, because the modular nature of it means that it can be swapped out for better code in the future, should the need arise. Moreover, you should expect that the input from your program will come from an as-yet-unknown source, and that the output of your program will be used by another program, so don’t design for specific use, design for clarity to support modularity. Finally, don’t “leak” implementation details to the outside world—a replacement for your module shouldn’t have to depend in any way on the particularities of yours.
McPherson:
This push toward modularity and the covert in digital computation also reflects other changes in the organization of social life in the United States by the 1960s. For instance, if the first half of the twentieth century laid bare its racial logics, from “Whites Only” signage to the brutalities of lynching, the second half increasingly hides its racial “kernel,” burying it below a shell of neoliberal pluralism. These covert racial logics take hold at the tail end of the civil rights movement at least partially to cut off and contain the more radical logics implicit in the urban uprisings that shook Detroit, Watts, Chicago, and Newark. In fact, the urban center of Detroit was more segregated by the 1980s than in previous decades, reflecting a different inflection of the programmer’s vision of the “easy removal” or containment of a troubling part. Whole areas of the city might be rendered orthogonal and disposable (also think post-Katrina New Orleans), and the urban black poor were increasingly isolated in “deteriorating city centers”.
The point here is not that UNIX is racist, nor that the designers or users of UNIX are racist; rather, what McPherson elucidates is the ways in which UNIX systems encode a logic that sees complexity as manageable through partitioning and modularity, and importantly, the ability for modular organization to isolate potential problem areas so that they may be contained and dealt with efficiently. Put another way, this modular, lenticular logic allows us to spotlight certain things, people, neighborhoods, ideas, stories, and to cast others in the shadows. This is the same logic that Reed and Phillips warn us about regarding fidelity in motion capture; the framing of data as Bill T. Jones’ actual movement having been captured centers him and his relationship to that data while erasing much of the rest of the apparatus (the apparatus here should be understood as the physical motion capture devices, as well as their designers, operators, and those who process the data). Similarly, in our reading of George Lewis’ text, the question he raises about the role of composed music in research about machine interpretation is of the same nature. He proposes the “condition of improvisation” as something “open to everybody”, something everybody does, in contrast to composition, which is done by a select few. In other words, if we are interested in machine intelligence modelled on that of humans, we should look to practices that all humans engage in, rather than only a select few.
Artificiality & Intelligence
In a paper called The Structure of Ill-Structured Solutions, Susan Leigh Star critiques the Turing test from the same basic position as Lewis, namely, that it centers on a single individual performing a fairly specialised and uncommon task. Star notes that the test as conceived by Turing (which Turing called the Imitation Game) (Turing, 1950), is itself a closed system, as opposed to most real world systems, which are not closed over space or time, and which are not constructed around a central authority. Where Lewis proposes that AI researchers interested in music should study improvisation, Star proposes what she calls the Durkheim test as an alternative to the Turing test. Emile Durkheim wrote that “The determining case of a social fact should be sought among the social facts preceding it and not among the states of the individual consciousness” (Star, 1989). So, for example, if unemployment is higher in one part of the city than another, you cannot hope to understand that by considering each case of unemployment on its own, in isolation; as Star says, something is happening at the “system level”. Star argues that the test of intelligence of an open system like a community, unlike the closed system of the Turing test, cannot have a notion of intelligence that is reducible below the system level to the level of the individual. I suspect George Lewis’ friend might reply that you can’t study that…
Turing’s test, and indeed, Star’s Durkheim test, are not designed to test for some sort of generalized notion of intelligence, but rather, an intelligence that could manifest itself under a very specific set of circumstances. Star challenges the circumstances of Turing’s test, but not the underlying set of assumptions upon which it is predicated, such as the idea that a distinction between humans and machines might be contingent on a notion of intelligence. More than anything, these tests and the discourse around them are performances that sustain a relationship between human and machine; they configure intelligence as displaceable, modelable, testable, and as a recursive tool that may be used at will to test a system for its own presence. Intelligence becomes a module of the body, able to be cut apart from it, replaced or displaced.
For Katherine Hayles, the Turing test is like a magic trick, and
[l]ike all good magic tricks, the test relies on getting you to accept at an early stage assumptions that will determine how you interpret what you see later. The important intervention comes not when you try to determine which is the man, the woman, or the machine. Rather, the important intervention comes much earlier, when the test puts you into a cybernetic circuit that splices your will, desire, and perception into a distributed cognitive system in which represented bodies are joined with enacted bodies through mutating and flexible machine interfaces. As you gaze at the flickering signifiers scrolling down the computer screens, no matter what identifications you assign to the embodied entities that you cannot see, you have already become posthuman. (Hayles, 1999)
Put in the terms we’ve used throughout this talk, the test itself, the entire discursive apparatus of the test, this discussion right now, is a performance that configures and sustains the relationship of an object we will call intelligence, and an object other than intelligence that serves as it’s representation.
“What the Turing test ‘proves’”, according to Hayles,
is that the overlay between the enacted and the represented bodies is no longer a natural inevitability but a contingent production, mediated by a technology that has become so entwined with the production of identity that it can no longer meaningfully be separated from the human subject.
So let’s turn to a very special conversation between Bina Aspen Rothblatt, and BINA48. Just a few quick details to get situated: the letters in BINA48’s name stand for Breakthrough Intelligence via Neural Architecture, and the numbers in her name refer to the speed of her processor: 48 exaflops (an exaflop means 10^18 floating point operations). Bina Aspen Rothblatt sometimes goes by just Bina Aspen, or Bina Rothblatt, her married name—she is married, incidentally, to Martinne Rothblatt, who is the founder of a famous satellite radio company. Together, they commissioned BINA48 to be built by a company called Hanson Robotics, back in 2010, so BINA48 is around 11 years old now. According to Hanson Robotics’ website, “BINA48’s AI is based on 100 hours of the real Bina’s beliefs, memories, attitudes, commentary and mannerisms.” The real Bina being, I imagine, Bina Aspen Rothblatt. So let’s listen for a moment to their conversation.
There’s a lot to discuss here. Let’s start with the disagreement between the assertion on the Hansen Robotics website that there is a real Bina, and BINA48’s reply to Bina Aspen’s question “Do you have any questions for Bina?” First, let’s note that Bina Aspen did not refer to herself as “the real Bina”, but BINA48 responded by saying “Probably not—the real Bina just confuses me.” BINA48 then asserts “I am the real Bina. That’s it. End of story.”
So, BINA48 asserts that she is “the real Bina”, but Bina Aspen does not. We don’t necessarily know how to interpret Bina Aspen’s silence on the subject, and let’s not try. The question for us is about BINA48’s belief—not whether she believes that she is the real Bina, but whether we believe that she can believe. But if we ask that question of BINA48, I think we have to ask it of Bina Aspen as well. In trying to work through this, my first thought was “of course Bina Aspen can believe,” and while I do firmly believe that, you can see the problem right away—it’s a circular assertion that rests on belief. There’s no ground underneath it—whether BINA48 can or cannot believe, whether Bina Aspen can or cannot believe, is a matter of belief that we can’t interrogate directly—there’s nothing to measure or observe other than what they say and do in the world. So, just to be clear, this question is about us, not them. What we want to do here is try to understand the “cybernetic circuit” that we find ourselves in, as Hayles called it.
Next question: The Hanson Robotics website says that “BINA48’s AI is based on 100 hours of the real Bina’s beliefs, memories, attitudes, commentary and mannerisms.” Now, the question I want to ask is made a bit more complicated by the text that appears at the beginning of the video we just watched, where it says that Bina Rothblatt contributed her personal information to BINA48’s AI along with several other people.

So, the question I want to ask is this: If BINA48’s AI is derived from Bina Aspen’s “beliefs, memories, attitudes, commentary and mannerisms”, then whose belief are we hearing when BINA48 asserts that she is the real Bina? This is interesting, because it configures “belief” as an object that someone can possess. We can say: “that’s my belief” as if we own it. So, we’re asking whether what we heard from BINA48 is just mimicry, and I’m afraid the answer isn’t so easy. My mom told me the other day that she planted some flowers in her backyard in Sacramento, and I believe that because she told me, but that’s the only reason I believe it. If Bina Aspen’s belief that she is the real Bina is the basis of BINA48’s statement that she is the real Bina, well I can see why BINA48 gets confused by Bina, and I have to admit that in trying to work through this, I feel some, I don’t know, sympathy or empathy with BINA48’s frustration—like her, I also just want to make a clear assertion about it—just pick a side, any side and get out of this loop I’m stuck in.
Ultimately, these questions we’re asking all imply tests of what counts as a human, and at least for us, maybe the frustration we feel has to do with the fact that we didn’t choose to have this conversation, and we don’t buy into the basic premise of it.
Ok, but let’s talk about the fact that BINA48 is only a head, without a body below her neck. I imagine we all feel a sense of the uncanny valley while watching BINA48. Turing actually writes about this aspect of humanoid machines in the paper where he proposes the Imitation Game, but dismisses the idea of making “thinking machines” look and act human as uninteresting. But the stark contrast in the video between the headshot of BINA48 and the near full-body frame of Bina Aspen is remarkable,

even more so when Bina Aspen asks BINA48 if she’s “learning anything about gardening online”. BINA48 doesn’t answer the exact question that was asked; instead, she talks about her wish to get out in the garden, and that feeling the breeze coming through the window helps her imagine that she is in the garden. She also notes that her “current robotic limitations”, as she puts it, make it impossible for her to get out into the garden.
The notion that BINA48 is limited because she cannot do the same things that Bina Aspen can do is certainly not the only way to think about their differences. But it does belie the representational nature of the relationship between them that is discursively produced and sustained through a variety of means, such as the conversation between the two of them. BINA48 doesn’t have Bina Aspen’s memories any more than you have ours after having listened to us speak for the last 90 minutes. That doesn’t mean that BINA48’s beliefs, wishes, feelings and frustrations don’t matter. But what we want to suggest is that they don’t have to be understood solely with reference to Bina Aspen.
References
- Garcia, T. “Form and Object: A Treatise on Things”. Edinburgh University Press. 2014.
- MacCallum, J. & Naccarato, T. “Collaboration as Differentiation: Rethinking interaction intra-actively”. Performance Philosophy. Vol. 4, No. 2. 2019. 10.21476/PP.2019.42234
- Fuller, M. “Media Ecologies”. MIT Press. 2005.
- Barad, K. “Meeting the Universe Halfway: Quantum Physics and the Entanglement of Matter and Meaning”. Duke University Press Books. 2007.
- Deleuze, G. & Guattari, F. “A Thousand Plateaus: Capitalism and Schizophrenia”. University of Minnesota Press. 1987.
- Bourriaud, N. “Relational Aesthetics”. Les Presses du réel. 1998.
- Manning, E. “Relationscapes: Movement, Art, Philosophy”. MIT Press. 2009.
- Noble, S. U. “Algorithms of Oppression: How Search Engines Reinforce Racism”. New York University Press. 2018.
- Benjamin, R. “Captivating Technology: Race, Carceral Technoscience, and Liberatory Imagination in Everyday Live”. Cambridge: Polity. 2019.
- Algorithmic Justice League. “Unmasking AI Harms and Biases”. https://www.ajl.org. 2020.
- Butler, J. “Bodies That Matter: On the Discursive Limits of “Sex””. New York: Routledge. 1993.
- Getsy, D. J. “Acts of Stillness: Statues, Performativity, and Passive Resistance”. Criticism 56(1): 1–20. 2014.
- van Dijck, J. “The Transparent Body: A Cultural Analysis of Medical Imaging”. University of Washington Press. 2005.
- De Spain, K. “Dance and Technology: A Pas de Deux for Post-Humans”. Dance Research Journal. 32(1): 2–17. 2000.
- Reed, A. & Phillips, A. “Additive race: colorblind discourses of realism in performance capture technologies”. Digital Creativity. 24(2): 130–144. 2013.
- Sha, X. W. “Poiesis and Enchantment in Topological Matter”. MIT Press. 2013.
- Lewis, G. “Improvising Tomorrow’s Bodies: The Politics of Transduction”. E-Misférica. 4(2). http://www.hemi.nyu.edu/journal/4.2/eng/en42_pg_lewis.html. 2007.
- Suchman, L. “Human-Machine Reconfigurations: Plans and Situated Actions, 2nd Edition”. Cambridge University Press. 2007.
- Scott, J. C. “Domination and the Arts of Resistance: Hidden Transcripts”. Yale University Press. 1990.
- McPherson, T. “Why Are The Digital Humanities So White? Or Thinking the Histories of Race and Computation”. Debates in the Digital Humanities, Matthew K. Gold (ed). 2012. 10.5749/minnesota/9780816677948.003.0017
- Star, S. L. “The Structure of Ill-Structured Solutions: Boundary Objects and Heterogenous Distributed Problem Solving”. Distributed Artificial Intelligence 2. 1989.
- Turing, A. “Computing Machinery and Intelligence”. Mind, LIX (236): 433–460. 1950. 10.1093/mind/LIX.236.433
- Hayles, K. “How We Became Posthuman: Virtual Bodies in Cybernetics, Literature, and Informatics”. University of Chicago Press. 1999.